Code
Projects
Semantic Richness or Geometric Reasoning? The Fragility of VLM’s Visual Invariance
Generative Action Tell-Tales: Assessing human motion in synthesized videos
Some Modalities are More Equal Than Others: Decoding and Architecting Multimodal Integration in MLLMs
What’s in a Latent? Leveraging Diffusion Latent Space for Domain Generalization
Revelio: Interpreting and leveraging semantic information in diffusion models
Progressive Prompt Detailing for Improved Alignment in Text-to-Image Generative Models
edubotics-core: An Open-Source Python Library for Building LLM-based Applications
edubotics-core is an open-source Python library that allows developers to build LLM-based chatbots efficiently. It provides a comprehensive set of core modules for vector storage, retrieval, processing, with more to come.

Installation:
pip install edubotics-core
Code: https://github.com/edubotics-ai/edubotics-core
Full Documentation: http://docs.edubotics.ai
Applications built with edubotics-core: https://github.com/edubotics-ai/edubotics-app
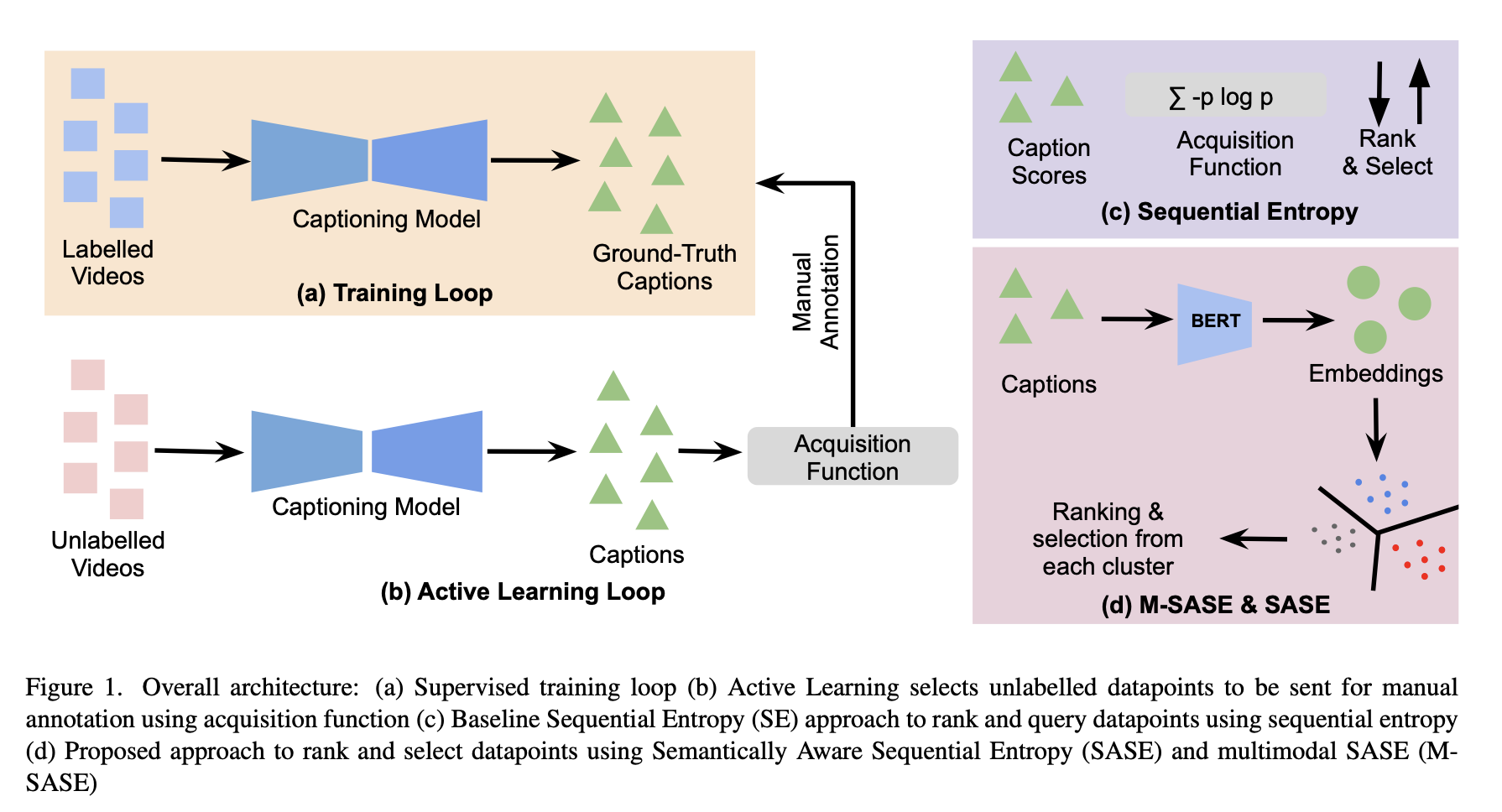
MAViC: Multimodal Active Learning for Video Captioning
A large number of annotated video-caption pairs are required for training video captioning models, resulting in high annotation costs. Active learning can be instrumental in reducing these annotation requirements. However, active learning for video captioning is challenging because multiple semantically similar captions are valid for a video, resulting in high entropy outputs even for less-informative samples. Moreover, video captioning algorithms are multimodal in nature with a visual encoder and language decoder. Further, the sequential and combinatorial nature of the output makes the problem even more challenging. In this work, we introduce MAViC which leverages our proposed Multimodal Semantics Aware Sequential Entropy (M-SASE) based acquisition function to address the challenges of active learning approaches for video captioning. Our approach integrates semantic similarity and uncertainty of both visual and language dimensions in the acquisition function. Our detailed experiments empirically demonstrate the efficacy of M-SASE for active learning for video captioning and improve on the baselines by a large margin.
Full Paper: https://arxiv.org/abs/2212.11109
AdaClust: Adaptive Methods for Aggregated Domain Generalization
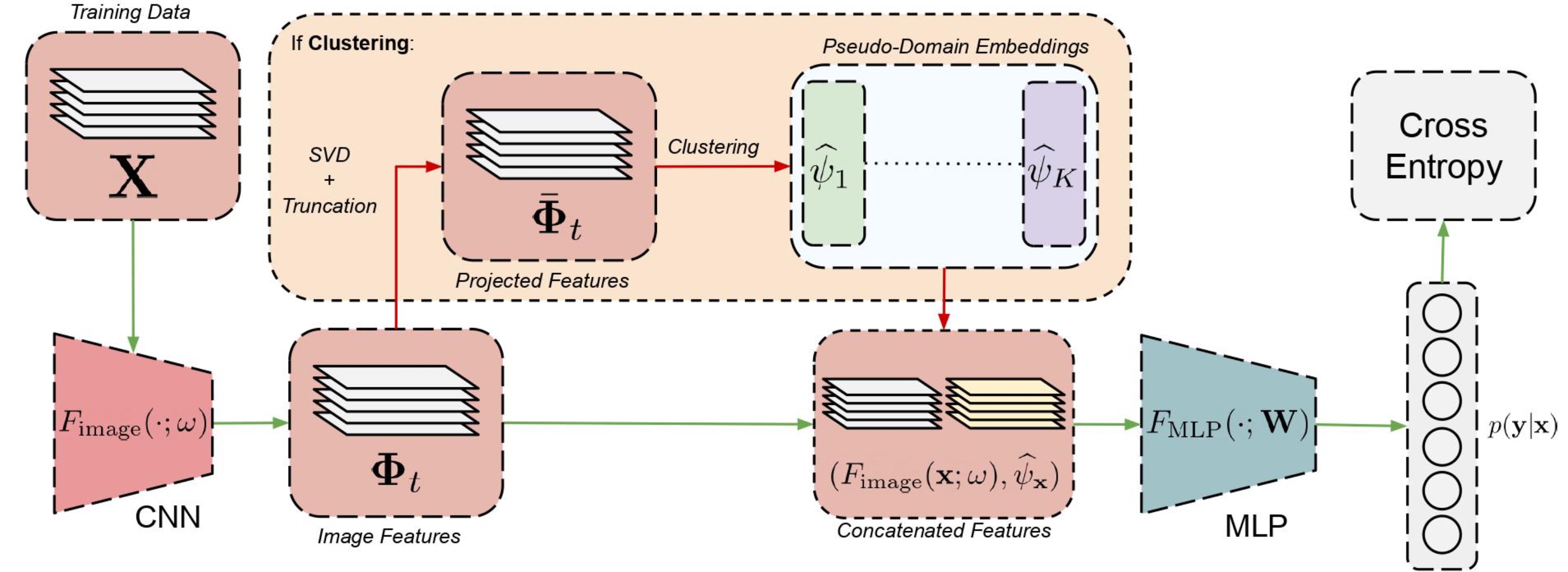
Domain generalization involves learning a classifier from a heterogeneous collection of training sources such that it generalizes to data drawn from similar unknown target domains, with applications in large-scale learning and personalized inference. In many settings, privacy concerns prohibit obtaining domain labels for the training data samples, and instead only have an aggregated collection of training points. Existing approaches that utilize domain labels to create domain-invariant feature representations are inapplicable in this setting, requiring alternative approaches to learn generalizable classifiers. In this work, we propose a domain-adaptive approach to this problem, which operates in two steps: (a) we cluster training data within a carefully chosen feature space to create pseudo-domains, and (b) using these pseudo-domains we learn a domain-adaptive classifier that makes predictions using information about both the input and the pseudo-domain it belongs to. Our approach achieves state-of-the-art performance on a variety of domain generalization benchmarks without using domain labels whatsoever. Furthermore, we provide novel theoretical guarantees on domain generalization in using cluster information. Our approach is amenable to ensemble-based methods and provides substantial gains even on large-scale benchmark datasets.
Full Paper: https://arxiv.org/abs/2112.04766
Code: https://github.com/xavierohan/AdaClust_DomainBed
Diversity vs. Recognizability: Human-like generalization in one-shot generative models
Robust generalization to new concepts has long remained a distinctive feature of human intelligence. However, recent progress in deep generative models has now led to neural architectures capable of synthesizing novel instances of unknown visual concepts from a single training example. Yet, a more precise comparison between these models and humans is not possible because existing performance metrics for generative models (i.e., FID, IS, likelihood) are not appropriate for the one-shot generation scenario. Here, we propose a new framework to evaluate one-shot generative models along two axes: sample recognizability vs. diversity (i.e., intra-class variability). Using this framework, we perform a systematic evaluation of representative one-shot generative models on the Omniglot handwritten dataset. We first show that GAN-like and VAE-like models fall on opposite ends of the diversity-recognizability space. Extensive analyses of the effect of key model parameters further revealed that spatial attention and context integration have a linear contribution to the diversity-recognizability trade-off. In contrast, disentanglement transports the model along a parabolic curve that could be used to maximize recognizability. Using the diversity-recognizability framework, we were able to identify models and parameters that closely approximate human data.
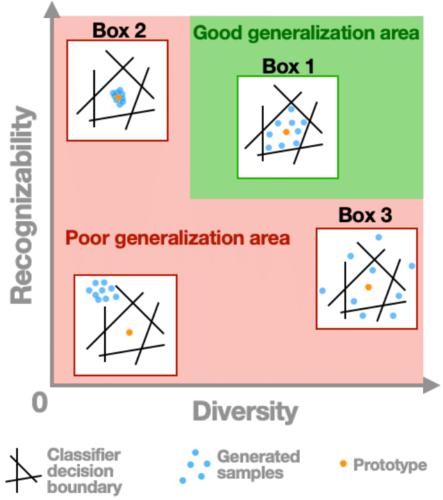
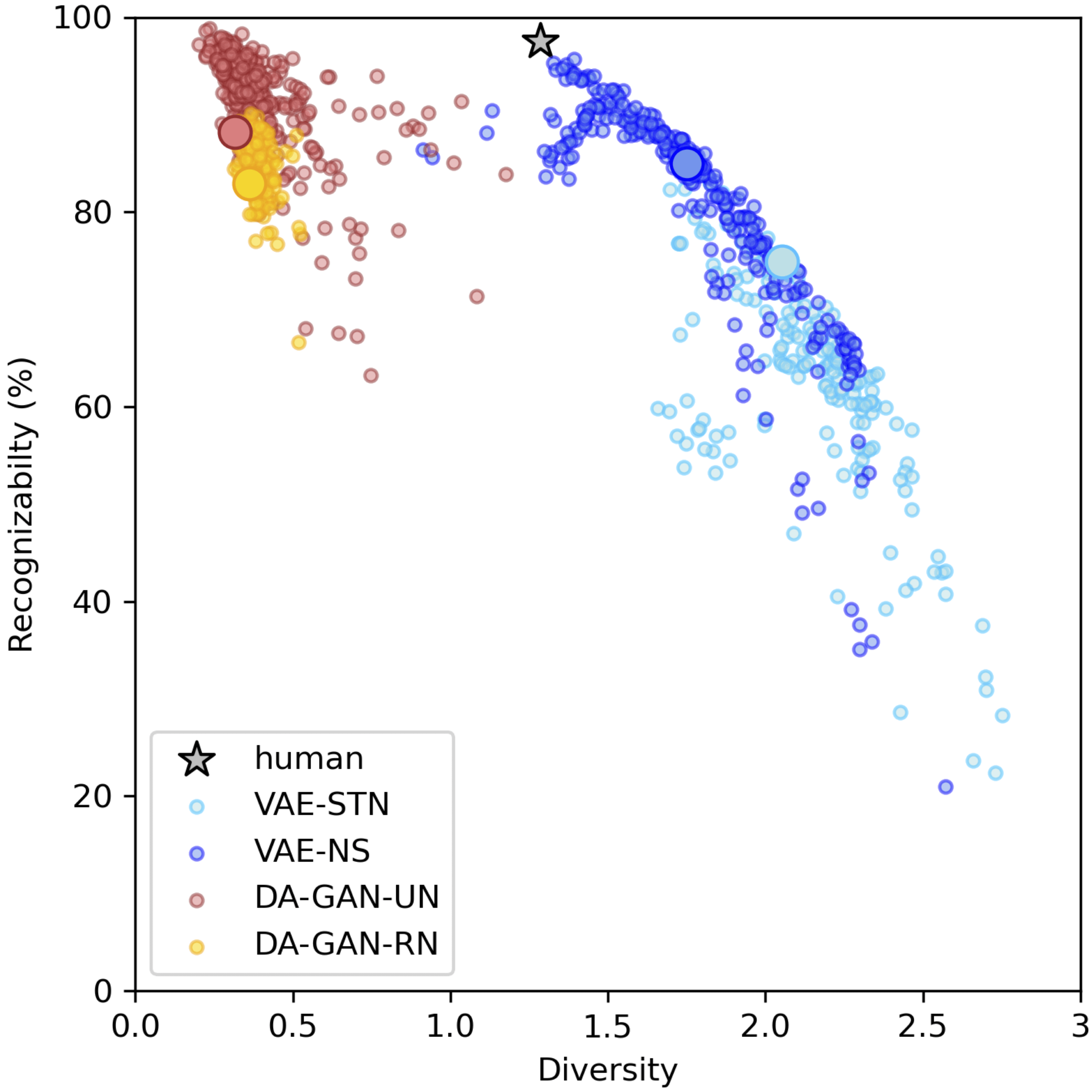
Full Paper: https://arxiv.org/abs/2205.10370
Code: https://github.com/serre-lab/diversity_vs_recognizability